We are working on updating this book for the latest version. Some content might be out of date.
The common_grams token filter is designed to make phrase queries with
stopwords more efficient.
It is similar to the shingles token
filter (see
Finding Associated Words), which creates bigrams out of every pair of adjacent words. It
is most easily explained by example.
The common_grams token filter produces different output depending on whether
query_mode is set to false (for indexing) or to true (for searching), so
we have to create two separate analyzers:
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"index_filter": {  "type": "common_grams",
"common_words": "_english_"
"type": "common_grams",
"common_words": "_english_"  },
"search_filter": {
},
"search_filter": { 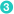 "type": "common_grams",
"common_words": "_english_",
"type": "common_grams",
"common_words": "_english_",  "query_mode": true
}
},
"analyzer": {
"index_grams": {
"query_mode": true
}
},
"analyzer": {
"index_grams": {  "tokenizer": "standard",
"filter": [ "lowercase", "index_filter" ]
},
"search_grams": {
"tokenizer": "standard",
"filter": [ "lowercase", "index_filter" ]
},
"search_grams": {  "tokenizer": "standard",
"filter": [ "lowercase", "search_filter" ]
}
}
}
}
}
"tokenizer": "standard",
"filter": [ "lowercase", "search_filter" ]
}
}
}
}
}
|
First we create two token filters based on the |
|
The |
| Then we use each filter to create an analyzer for index time and another for query time. |
With our custom analyzers in place, we can create a field that will use the
index_grams analyzer at index time:
PUT /my_index/_mapping/my_type
{
"properties": {
"text": {
"type": "string",
"index_analyzer": "index_grams",
"search_analyzer": "standard"
}
}
}
|
The |
If we were to analyze the phrase The quick and brown fox with shingles, it would produce these terms:
Pos 1: the_quick Pos 2: quick_and Pos 3: and_brown Pos 4: brown_fox
Our new index_grams analyzer produces the following terms instead:
Pos 1: the, the_quick Pos 2: quick, quick_and Pos 3: and, and_brown Pos 4: brown Pos 5: fox
All terms are output as unigrams—the, quick, and so forth—but if a word is a
common word or is followed by a common word, then it also outputs a bigram in
the same position as the unigram—the_quick, quick_and, and_brown.
Because the index contains unigrams, the field can be queried using the same techniques that we have used for any other field, for example:
GET /my_index/_search
{
"query": {
"match": {
"text": {
"query": "the quick and brown fox",
"cutoff_frequency": 0.01
}
}
}
}The preceding query string is analyzed by the search_analyzer configured for the
text field—the standard analyzer in this example—to produce the
terms the, quick, and, brown, fox.
Because the index for the text field contains the same unigrams as produced
by the standard analyzer, search functions as it would for any normal
field.
However, when we come to do phrase queries,
we can use the specialized
search_grams analyzer to make the process much more efficient:
GET /my_index/_search
{
"query": {
"match_phrase": {
"text": {
"query": "The quick and brown fox",
"analyzer": "search_grams"
}
}
}
}
|
For phrase queries, we override the default |
The search_grams analyzer would produce the following terms:
Pos 1: the_quick Pos 2: quick_and Pos 3: and_brown Pos 4: brown Pos 5: fox
The analyzer has stripped out all of the common word unigrams, leaving the common word
bigrams and the low-frequency unigrams. Bigrams like the_quick are much
less common than the single term the. This has two advantages:
-
The positions data for
the_quickis much smaller than forthe, so it is faster to read from disk and has less of an impact on the filesystem cache. -
The term
the_quickis much less common thanthe, so it drastically decreases the number of documents that have to be examined.
There is one further optimization. By far the majority of phrase queries consist of only two words. If one of those words happens to be a common word, such as
GET /my_index/_search
{
"query": {
"match_phrase": {
"text": {
"query": "The quick",
"analyzer": "search_grams"
}
}
}
}then the search_grams analyzer outputs a single token: the_quick. This
transforms what originally could have been an expensive phrase query for the
and quick into a very efficient single-term lookup.