We are working on updating this book for the latest version. Some content might be out of date.
A single predominant language per document
requires a relatively simple setup.
Documents from different languages can be stored in separate indices—blogs-en,
blogs-fr, and so forth—that use the same type and the same fields for each index,
just with different analyzers:
PUT /blogs-en
{
"mappings": {
"post": {
"properties": {
"title": {
"type": "string",  "fields": {
"stemmed": {
"type": "string",
"analyzer": "english"
"fields": {
"stemmed": {
"type": "string",
"analyzer": "english"  }
}}}}}}
PUT /blogs-fr
{
"mappings": {
"post": {
"properties": {
"title": {
"type": "string",
}
}}}}}}
PUT /blogs-fr
{
"mappings": {
"post": {
"properties": {
"title": {
"type": "string", 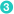 "fields": {
"stemmed": {
"type": "string",
"analyzer": "french"
"fields": {
"stemmed": {
"type": "string",
"analyzer": "french"  }
}}}}}}
}
}}}}}}
|
Both |
|
The |
This approach is clean and flexible. New languages are easy to add—just create a new index—and because each language is completely separate, we don’t suffer from the term-frequency and stemming problems described in Pitfalls of Mixing Languages.
The documents of a single language can be queried independently, or queries
can target multiple languages by querying multiple indices. We can even
specify a preference
for particular languages with the indices_boost parameter:
GET /blogs-*/post/_search
|
This search is performed on any index beginning with |
|
The |
|
Perhaps the user’s |
Of course, these documents may contain words or sentences in other languages, and these words are unlikely to be stemmed correctly. With predominant-language documents, this is not usually a major problem. The user will often search for the exact words—for instance, of a quotation from another language—rather than for inflections of a word. Recall can be improved by using techniques explained in Normalizing Tokens.
Perhaps some words like place names should be queryable in the predominant language and in the original language, such as Munich and München. These words are effectively synonyms, which we discuss in Synonyms.